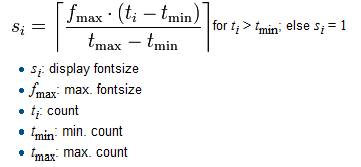研究方法
一、研究對象
對象:國立新竹教育大學 中文系二年級
隨機抽樣24位,共計16男,8女。年齡約為19至20歲。
地點:教室。
二、實驗流程
本實驗採一對一的方式進行。訪談過程中首先詢問「觀看這張圖像請問看到或感覺到什麼?」,並用紙筆方式依序寫下受測者所講的語詞,並詢問是在圖中的哪個位置激發語詞。若受測者猶豫無法依照直覺回答,及不再繼續往下受測。
三、研究方法
1.subject-w-form:
受測時依序記錄每位受測者所說的詞語,並利用subject-w-form表格將所有詞語依序填入,根據本實驗subject-w-form表格所填寫的語詞,可以觀測出受測者說出語詞的順序,並有利於作為之後實驗所產生的「詞頻表」及「標籤雲(Tag cloud)」實驗的產出。
2.詞頻表:
根據subject-w-form表格所記錄受測者所說的詞語,將語意相近的詞語,歸納為同一類,將蒐集到的詞語計算其個數並統整為詞頻表。詞頻表可以提供語詞出現的頻率,並歸納出根據圖像會出現多少相關語詞。
3. KJ法:
KJ這個名稱是創始人川喜田二郎(Kawakita Jiro)先生(文化人類學家,開發的當時為東京工業大學教授)取英文姓名起首的字母,由創造性研究團體「日本獨創性協會」命名的。KJ法集大成出自「KJ法──渾混談」(川田喜二郎著,中央公論社,一九八六年)一書。
最基本的狹義KJ法的步驟,大略步驟如下:
將所有蒐集到的語詞皆利用KJ法的分析方式,建構成語意地圖(Semantic map)。每個KJ法分析出來類別都使用一個Node替代,並計算此Node出現的次數,並用線條長度代表語詞出現的強度頻率。
4、spearding activation:
本研究還特別注意到spearding activation語意產生時的激發點與其順序。並將其受測者提供語意的順序記錄下來。
5、畫面座標圖分析:(後測增加分析)
將所有語意產出的激發點記錄到圖像中的相關位置,以利之後可以方便尋找較遠的語意出現在圖中的相關位置,完成語意地圖。
6、標籤雲(Tag cloud):(後測增加分析)
標籤雲或文字雲是關鍵詞的視覺化描述。將所有蒐集到的語詞,將每個語詞出現次數,利用以下公式帶入,算出語詞出現的頻率,透過語詞出現頻率區分其字體大小,並由此可知所有受測者觀看到圖像所產生的強弱順序。