|
一:研究研究對象
對像:新竹忠孝國中 一年級國中生 共30人(男15人 女15人)
時間:16:00-16:45
地點:教室
二:研究方法
本實驗透過實驗分析方法顯示出現的字詞位置、頻率詞頻及字詞分類狀況。((1)~(3)部分同前測之方法(4)以KJ法分類呈現(5)為新增的部分
使用方法詳述如下:
(1)subject-w-form:
施測時透過錄音的方式記錄每位受試者所說出的語詞及語意出現的先後順序,再透過subject-w-form的表格將施測結果完整記錄下來。於subject-w-form的表格中可以明顯看出每位受試者的語詞表達狀況,同時也能觀察出語意出現的先後順序,此方式有助於之後的關鍵字詞出現頻率之統計及Tag Cloudy中關鍵詞的排序。
(2)詞頻表:
將subject-w-form中出現的字詞加以分類,把相關的詞語列出並利用代表字詞替代相關語詞,經統計數量後編製出詞頻表。從詞頻表的結果中可找出最常出現的關鍵字詞及各類字詞出現的頻率多寡,並從中了解到圖像內容產生關鍵字詞的狀況。
(3)KJ法與Semantic map:
KJ法是由「日本獨創性協會」創始人川田喜二郎(Kawakita Jiro)所創立的,是一種收斂型思考方式的卡片分類法(黃有翔,2009)。KJ法具有將不同性質的資料與情報加以歸納整理的統合性功能。KJ法使用流程如下
 : :
建置語意地圖(Semantic map):經過KJ法將結果分類成數個Node後,再以線條長短來顯示與圖形間的相關強度,其中線條包含了屬性與特徵,但無法從中了解到語意出現的先後順序狀況。
(4)畫面座標圖分析(KJ整體分類):
將施測後產生的關鍵字詞標註在圖像上的相關位置,透過關鍵字詞的依附下,便可觀察出受試者觀察圖像時物體的位置關係及激發語詞之數量。
(5)Tag cloud(後測新增):
Tag cloud是關鍵字詞視覺化的表示方式,透過字體大小的變化來呈現字詞出現的權重比例(維基百科,2010)。Tag cloud中語詞字體大小的計算公式為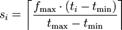 for ti > tmin; else si = 1。 for ti > tmin; else si = 1。
- si: 顯示的字體大小
- fmax: 最大的字體
- ti: 出現的次數
- tmin: 出現最少的次數
- tmax: 出現最多的次數
英文的關鍵字詞排列順序是依照英文字母出現順序去排列,由於中文字詞開頭的字並不能代表任何意義,因此中文關鍵字詞無法依照英文字詞的方式排序, 故此研究中Tag cloud關鍵字詞順序是由subject-w-form出現的關鍵字詞順序排列而成。
|
